Dynamic Maps, Static Storage
Update: This post describes the internals of the PMTiles v2 format. Check out the post on PMTiles V3 for the latest!
Serverless computing supposedly will let developers run sophisticated applications on the web without wrangling virtual machines or databases. New products like Lambda offer simpler deploys for code; emerging standards like WebAssembly let you host SQLite databases on GitHub pages and make queries all from your browser. These examples rely on developers adopting new workflows or programming environments. So what if I told you that you’ve been computing serverlessly without realizing it?
Behold this one megabyte embedded video, a clip from Powers of Ten: A Film Dealing with the Relative Size of Things in the Universe and the Effect of Adding Another Zero:
There’s a couple things going on here:
You can seek to timestamps using the embedded controls to see the Chicago lakefront at different scales; consider this an act of querying a read-only database via an index.
The video is a single file, hostable anywhere, and playable by all modern browsers.
If you open your browser’s development tools, you’ll see requests for specific byte offsets in the file with Range: headers.
This simple example highlights the ease of use of video; A video is thought of as a single unit of content, like a text file or photograph, and not a kind of trendy serverless tech.
Codecs make Video Easy
A remarkable aspect of the above example is that it’s a single megabyte, despite being made of hundreds of individual frames. Assuming each frame is a 200 kilobyte still, storing the eight second video as a directory of images would take fifty times the space!
We can expose the secrets of video codecs using ffmpeg:
ffmpeg -flags2 +export_mvs -i in.mp4 -vf codecview=mv=pf+bf+bb out.mp4

White arrows depict motion vectors for blocks of pixels: the codec exploits redundancy across data to efficiently encode a single archive. This is possible because most videos are not random noise; the contents of a single frame are highly predictive of the next frames.
A Map is just a Video
At first blush, a dynamic map on the web isn’t much like a video and more like a web service; something database-shaped and probably server-ish, despite being a read-only experience. The Web Map Tile Service standard defines a HTTP server API for serving up maps; map tiles on openstreetmap.org are accessed by Web Mercator Z/X/Y URLs.
Given the above encoding example though, let’s imagine if dynamic maps, like videos, were just archives of images, but with frames that traverse space instead of time.
Armed with this insight, we can invent a codec for map data with these goals:
It should be a single file. There are existing workflows to host maps on S3 by syncing individual tiles and directories, but this is inconvenient in the same way syncing tens of thousands of still video frames is inefficient.
It should work the same way for all scales, from a small area map of the Chicago lakefront to the entire Earth.
It should be as simple as possible for the Z/X/Y use case, and hold arbitrary raster or vector tiles, which rules out backwards-compatible formats like Cloud Optimized GeoTIFFs.
A necessary step in making this efficient is, like video encoding, to exploit redundancy across data. Any global-scale map system must acknowledge the earth is 70% ocean. Map image APIs already take advantage of this by special-casing solid blue PNG images.

PMTiles: Pyramids of Map Tiles
PMTiles is a single-file archive format for pyramids of map tiles that aims to be the simplest possible implementation for the above requirements. It has a short and sweet specification that I’ve made available in the public domain, along with BSD-licensed Python and JavaScript reference implementations.
Here’s a visual for how a simple PMTiles archive is organized:
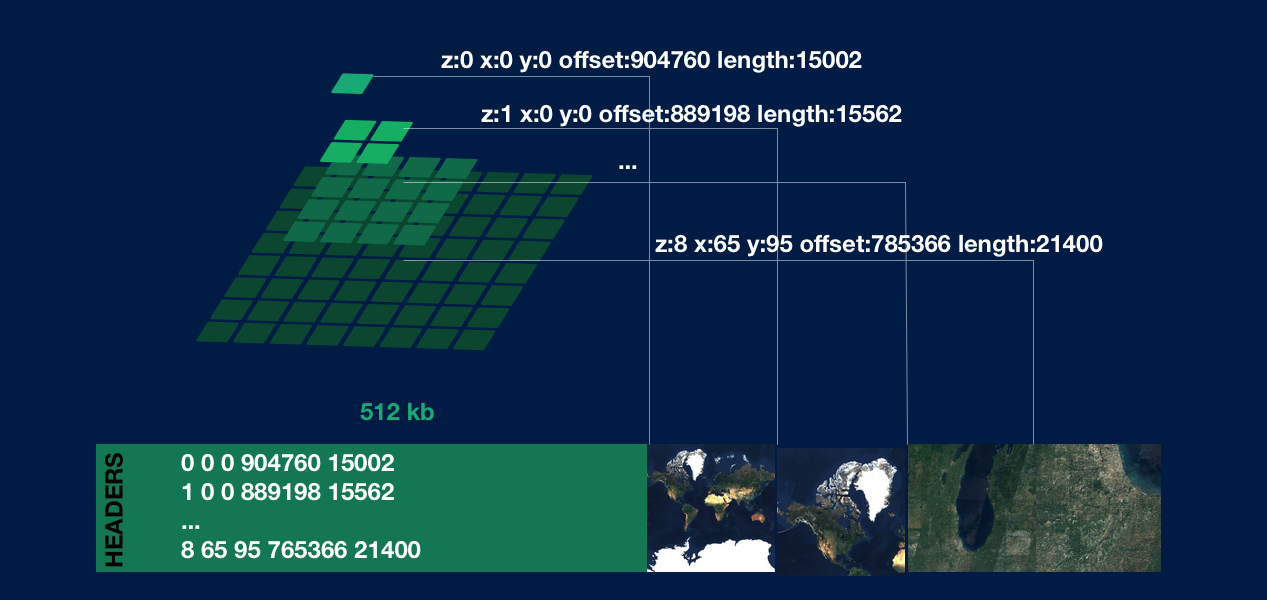
The process for fetching one tile like z:8 x:65 y:95:
Fetch the first 512 kilobytes and parse the directory into a lookup table
Look up by key of the tile you want, in this case
8_65_95It’s a match! You’ll have a byte range
offset: 785366 length: 21400Fetch those bytes using
Range:bytes=785366-806765and interpret the data as an image
Here’s an interactive example using the sub-200-line pmtiles.js decoder library in the browser, with Creative Commons satellite imagery from EOX’s S2 Cloudless product, containing some tiles covering our happy picnic on the Chicago lakefront:
pmtiles.getZxy(coord.z,coord.x,coord.y).then(result => {
let range = 'bytes=' + result[0] + '-' + (result[0]+result[1]-1)}
fetch('PowersOfTwo.pmtiles',{headers:{Range:range}).then(resp => {
return resp.arrayBuffer()
}).then(buf => {
var blob = new Blob( [buf], { type: "image/jpg" } )
var imageUrl = window.URL.createObjectURL(blob)
img.current.src = imageUrl
})
})
The initial fetch for the first 512 kilobytes is performed once and cached in the browser, so subsequent requests don’t incur the same overhead as the first tile. This again exploits the common panning+zooming access pattern, like what’s happening in this integration with Leaflet:
A consequence of the above design is that multiple entries can point to the same offset. A map of an island surrounded by lots of ocean will store our solid blue image once, with any number of tile entries referencing it. Multiple requests for this same offset will return our Blue Friend cached in the browser:
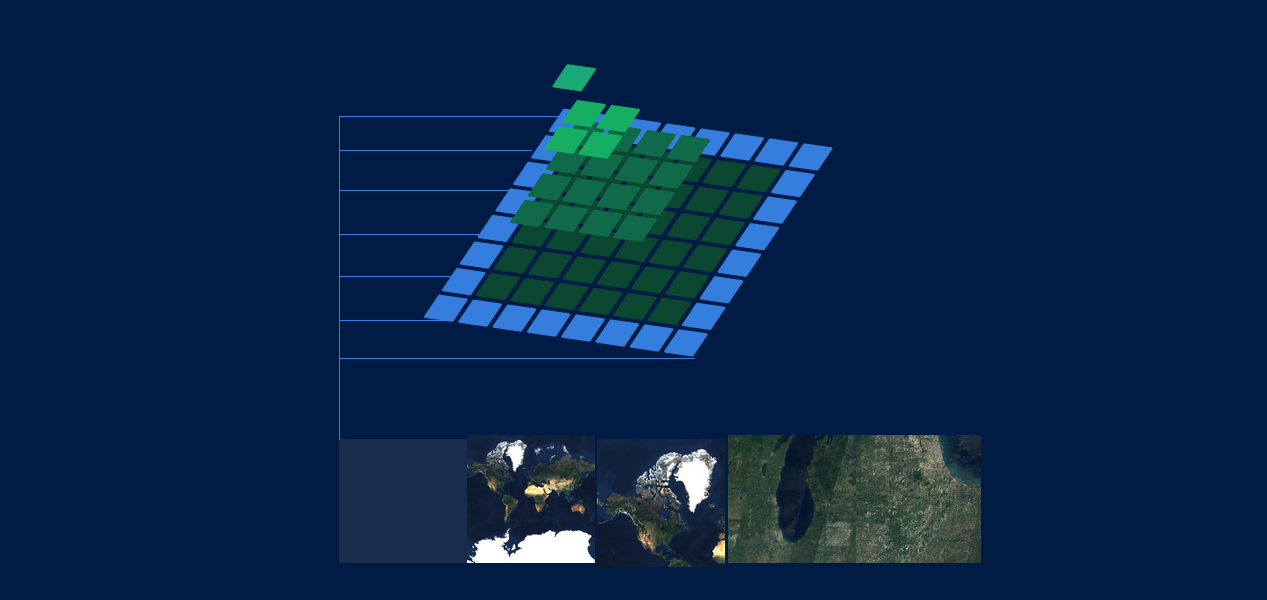
Adding more Zeros
The above example has a clear limitation, which is that the blind initial fetch is for only 512 kilobytes. A reasonable planet-scale map can have fifteen zoom levels; the sum count of tiles then is
1 + 4 + 16 + 64 + 256 + 1,024 + 4,096 + 16,384 + 65,536 + 262,144 + 1,048,576 + 4,194,304 + 1,6777,216 + 67,108,864 + 268,435,456
or 357,913,941 tiles. Given that PMTiles needs 17 bytes per entry, a full directory pyramid with 15 zoom levels is six gigabytes - impractical for any browser to fetch at once, especially if your map will only ever display a couple tiles!
We can solve this by adding a layer of indirection via leaf directories. A single directory in PMTiles has a hard cap of 21,845 entries, or a complete pyramid for eight zoom levels. At the maximum level of the root directory, the top bit of Z is flipped to describe the bytes at the referenced offset being not tile data but another directory with up to 21,845 entries.
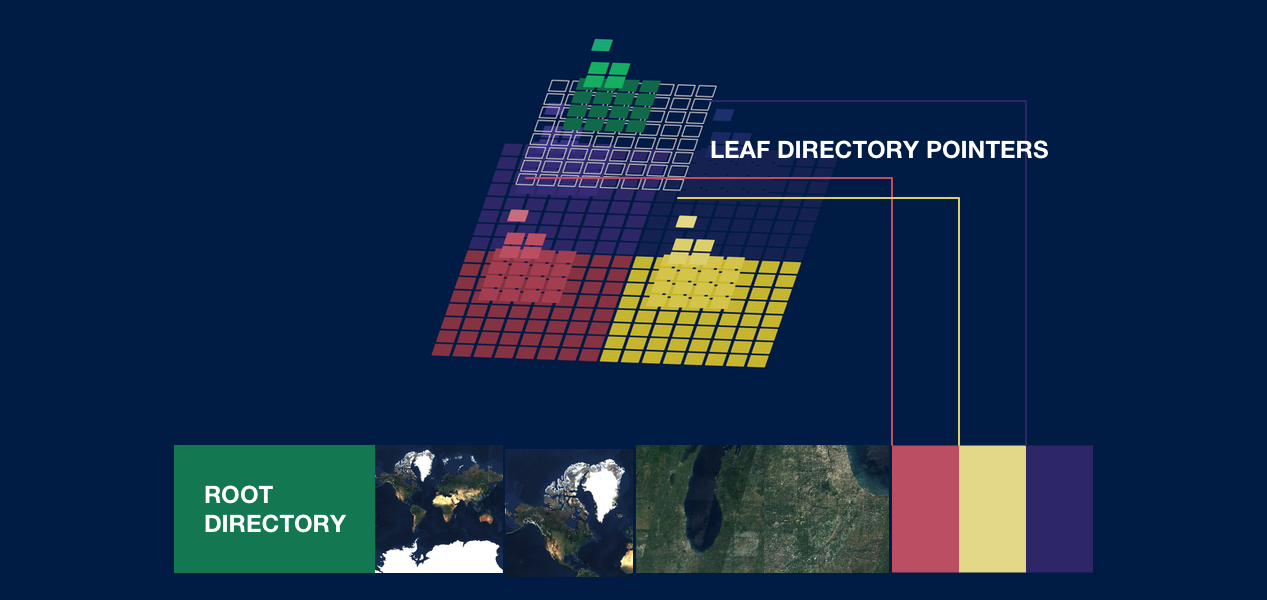
Example of how looking up z:14 x:4204 y:6090 works with leaf directories:
Fetch the first 512 kilobytes, parse the root directory.
Check the root directory for
14_4204_6090. It doesn’t exist, because the root directory only contains levels 0-7.Check the root directory for a leaf directory entry of the parent tile. The z7 parent tile of
z:14 x:4204 y:6090isz:7 x:32 y:47.Fetch the bytes for the leaf directory and parse it into a lookup table.
Index into the leaf directory with
14_4204_6090for the byte offset and length of the tile data.
As long as clients cache recently used lookup tables, and zooming/panning remains within z:7 x:32 y:47, no directory fetches are required after the first tile. The ideal ordering of tile data and leaf directories may be on space-filling curves to minimize hardware page faults, but this is an optimization and outside the spec.
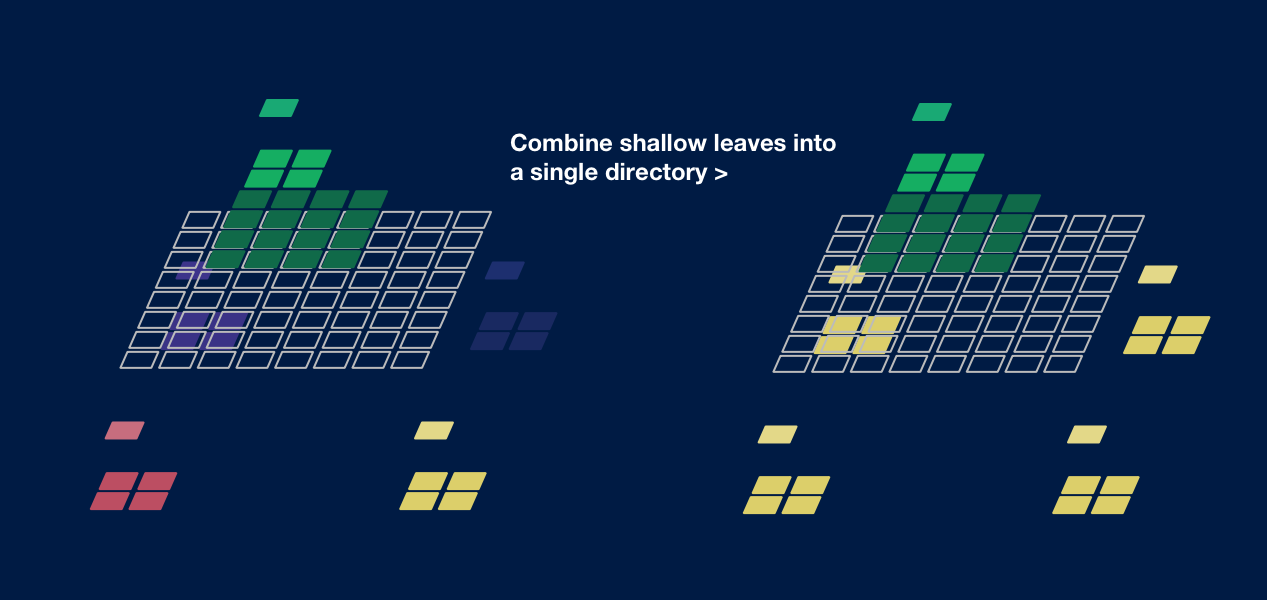
An astute reader will notice another seeming flaw in the above design: what if your pyramid is exactly a full nine levels? In this case, the root directory has a full 21,845 entries, and points to 16,384 leaf directories, each containing only five (one Z7 + four Z8) entries! Panning the map at Z7 would then incur a directory fetch for every single tile.
Inefficiently packed leaf directories can be solved the exact same way as duplicated ocean tiles. One leaf directory should contain multiple sibling sub-pyramids, up to 21,845 entries in total; the root directory then holds multiple leaf pointers to the same offset. As long as clients cache directories by offset and not ZXY, panning at Z7 will cost few extra fetches.
Here’s the limits implied by the 17 byte keys in PMTiles:
3 bytes for X and Y: maximum zoom of 23
6 bytes for offsets: maximum archive size of 281 terabytes
4 bytes for lengths: maximum individual tile size of 4.3 gigabytes
go-pmtiles: a PMTiles proxy
If you’re thinking, Yes Brandon, very clever design! We want to use this but all of our existing map systems read Z/X/Y tiles from a server… I’ve written a caching proxy that decodes your PMTiles on S3 via a traditional Z/X/Y endpoint. While no longer purely serverless, this is a two-megabyte executable that serves an entire bucket of PMTiles on a micro instance like this:
# to serve my-bucket/EXAMPLE_1.pmtiles and my-bucket/EXAMPLE-2.pmtiles...
go-pmtiles https://my-bucket.s3-us-east-1.amazonaws.com
> Serving https://my-bucket.s3-us-east-1.amazonaws.com on HTTP port: 8077
# fetch the tiles...
curl http://localhost:8077/EXAMPLE_1/0/0/0.jpg
curl http://localhost:8077/EXAMPLE_2/1/0/0.jpg
The details:
Inherits all the simplicity of PMTiles: a short, concurrent, evented Go program with zero runtime dependencies
Caches directories on the server to minimize latency on the client
Implements GZIP compression for uncompressed formats like vector Protobufs, since byte serving and Content-Encoding don’t play nicely together
You can download binary releases and source code at github.com/protomaps/go-pmtiles.
More Stuff
PMTiles is just one small part of Protomaps, a one-man project to rethink web cartography, and reflects many of the system’s core principles:
Less computation: “Serverless” patterns are here to stay: vendors achieve economies of scale; developers pay less; mapmaking projects outside of dedicated technology firms — by museums, cultural institutions, or journalists — can be preserved across time.
Dependency-free: Favor minimalist formats and statically-linked binaries over more features or backwards compatibility.
Scale-free: Tools and process knowledge for making an airport-sized map work the exact same way for a city, a country, and the entire Earth with no jumps in complexity.
If this system sounds interesting to you, you can reach me at brandon@protomaps.com or find me on Bluesky and Mastodon.
See also
MBTiles can deduplicate tiles via views, but must be accessed as a SQLite database.
W3C/OGC Joint Workshop Series on Maps for the Web addresses “Adding a native map viewer for the Web platform, similar to how HTML video was added for video content.”